


What Is DeepSeek-V3 and How Can It Help You?
The AI world is buzzing with innovations, and one of the stars of the show is DeepSeek-V3 — an advanced model designed to push boundaries in reasoning, writing, coding, and so much more, all while optimizing resource consumption. But as groundbreaking as it may sound, this model has some fascinating strengths, quirky techniques, and a few glaring weaknesses. Let’s take a detailed — and fun — journey into how this marvel works!
- Its Architecture (focusing on MLA and MTP)
- FP8 Training techniques designed to improve precision and save memory
- The pre-training pipeline that helps DeepSeek-V3 absorb trillions of tokens efficiently
- The post-training process, including its fine-tuning and learning strategies
- A quick look at its benchmarks and limitations
- A critical note on bias and ethical considerations
Architecture: The Genius Framework Behind DeepSeek-V3
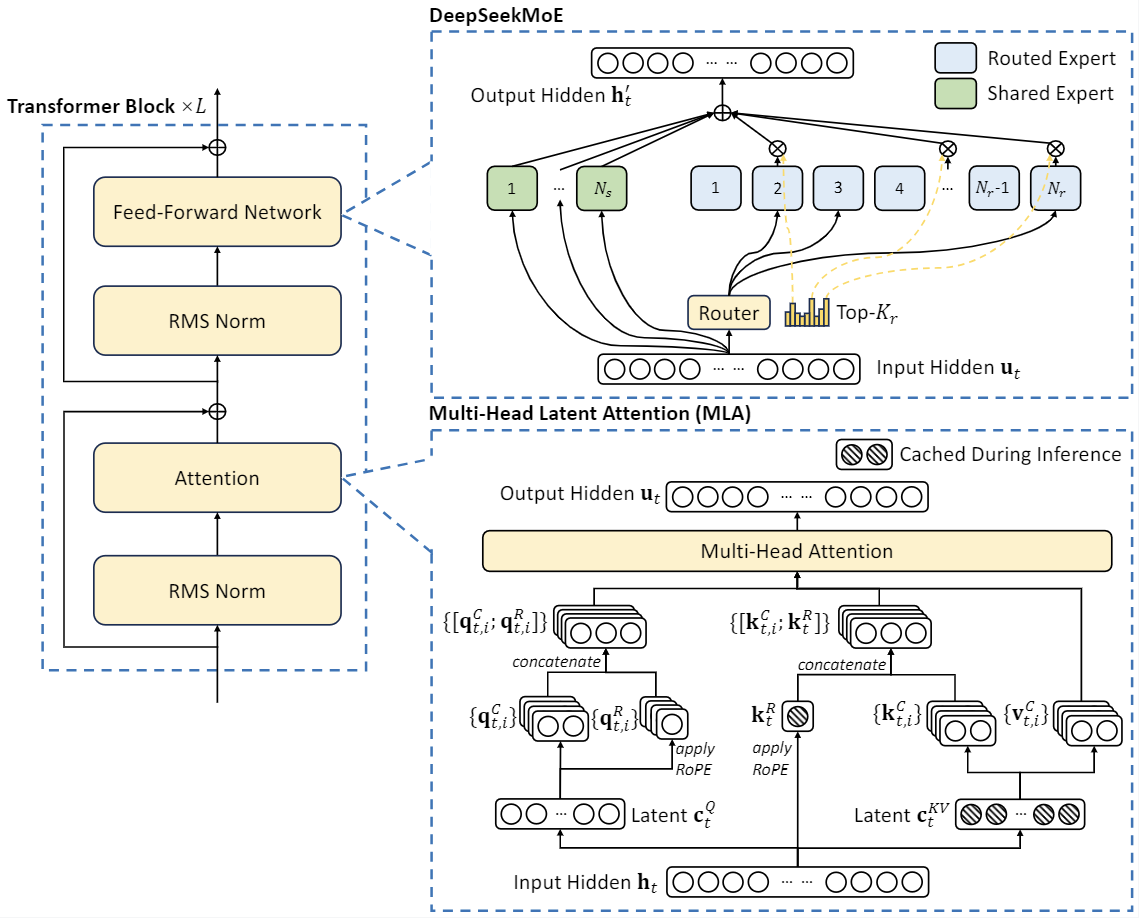
1. Multi-Head Latent Attention (MLA): Squashing Memory Costs Without Losing Performance
Picture this: you’re organizing a huge library with millions of books, each labeled with detailed codes. How do you manage these books efficiently without running out of space? MLA is like the “Marie Kondo” of AI design — it compresses data beautifully while retaining all critical details required for efficient memory use.
Traditional transformer-based models store every key-value (KV) pair during inference, hogging massive memory resources. Instead, MLA applies low-rank compression and shrinks the KV pairs into smaller, meaningful representations that still perform just as well. Think of this as packing the same travel essentials into lightweight bags for maximum efficiency.
MLA benefits:
- Saves memory without losing context.
- Greatly reduces inference costs.

DeepSeek Architecture (Source: – github)
2. Multi-Token Prediction (MTP): Faster and Smarter AI
AI models like GPT-3 predict text one word at a time, which is powerful but slow. MTP takes this to the next level by allowing DeepSeek-V3 to predict multiple tokens simultaneously. It’s like trying to solve a crossword puzzle with complete sentences instead of guessing just one word — much faster and more efficient!
Why is MTP better? Instead of: The → cat → sat, MTP predicts: The cat sat on the mat all at once.
This multi-token prediction capability not only improves inference speed but also sharpens the model’s ability to handle complex contextual threads.

Training Optimizations: How Efficiency Meets Accuracy
DeepSeek’s strengths don’t just come from its architecture. Its training process is structured to reduce costs and boost performance, from parallelization techniques to low-precision FP8 training. Let’s decode these optimizations:
FP8 Training: Precision Made Smarter
DeepSeek-V3 uses FP8 (Float 8-bit numbers) to increase computational speed and reduce memory use during training. But FP8 comes with challenges — it’s so small that there’s potential for errors in calculations. To address this, clever techniques are used:
1. Fine-Grained Quantization: Breaking into Small Pieces This is like packing your suitcase methodically — every item (or token) is grouped carefully so it fits perfectly. DeepSeek-V3 breaks data into smaller groups, each adjusted with specific multipliers to preserve precision. The result? Reliable training performance even with lower-bit precision.
2. Increasing Accumulation Precision: Adding Numbers More Accurately FP8 numbers, when added over and over, can accumulate random tiny errors. To fix this, DeepSeek temporarily upsizes intermediate calculations to FP32 (much more precise) before converting back to FP8. Think of this as pouring grains of rice into a larger bowl while counting them, then storing them in a smaller jar once you’re done counting.
3. Low-Precision Storage & Communication: Saving Space While Staying Stable FP8 data is great for quick and space-saving performance, but for delicate steps (like optimizer states), DeepSeek-V3 uses slightly better precision, such as BF16 numbers. It’s like writing shorthand for internal memos but keeping official documents in full detail.
Pre-Training Process: How DeepSeek Learns from the Internet
DeepSeek’s pre-training is like teaching a genius student — the model is fed 14.8 trillion tokens of high-quality, diverse text from all kinds of sources. But this massive learning process is managed efficiently with a few key tricks:
1. Document Packing: Optimizing Data Usage Instead of wasting training space on short chunks of text, DeepSeek packs multiple documents together into a batch—saving memory and speeding up performance.
Imagine playing Tetris with sentences — the unused gaps are minimized, ensuring no token is wasted!
2. Training Data: A World-Class Education for AI The model processes an enormous dataset of curated, high-quality text from literature, web articles, scientific journals, and more. Imagine training a chef with recipes from every global cuisine — DeepSeek is just as versatile.
3. Fill-in-the-Middle (FIM): Teaching Contextual Understanding FIM is a new pre-training approach where the model learns to predict missing words in the middle of a sentence using the surrounding context.
If given “The ___ is blue,” DeepSeek learns to infer the missing piece: “sky.”
This strategy stands out because most models only predict the next token, not missing ones.
4. Tokenizer: Breaking Words into Digestible Chunks The tokenizer breaks down long words into small, byte-level pieces for better processing. For example, “internationalization” becomes “inter-”, “national-”, and “-ization.”
DeepSeek’s tokenizer has 128,000 tokens, improving text understanding across multiple languages. It’s like breaking a long sentence into easier parts for transcription.
Some important numbers in the model:
61 Transformer layers (these help the model “think” in steps)
128 attention heads (each head focuses on different parts of the input)
671 billion total parameters (brainpower of the model, though only 37 billion are active at once)
MoE (Mixture of Experts) layers, where only a few specialized parts of the model are used for each token to save resources.
5. Model Structure: The Brainpower of DeepSeek-V3 DeepSeek is powered by:
- 61 layers of Transformers
- 128 attention heads across layers
- 671 billion parameters, though it intelligently activates only 37 billion at a time (this is due to its Mixture of Experts architecture).
This smart design reduces memory usage while ensuring excellent performance for reasoning, writing, and coding!
6. Optimizer: Ensuring the Model Learns Properly DeepSeek uses AdamW optimizer (basically the “fitness coach” of the AI world) to fine-tune the learning process while avoiding overfitting. The result: a balanced and well-adjusted model.
Post-Training: Fine-Tuning the Final Product
Once pre-training is done, post-training ensures the model becomes specialized for diverse tasks such as reasoning, creative writing, and role-play.
1. Supervised Fine-Tuning (SFT): Learning Through Examples
DeepSeek-V3 is fine-tuned on 1.5 million examples from domains like:
- Math
- Coding
- Writing Think of this phase as giving the model specific practice — like helping a brilliant math student refine their problem-solving skills.
2. Reinforcement Learning (RL): Rewarding Good Behavior
Reinforcement learning improves how the model decides on answers:
- For math and coding tasks (clear right/wrong answers), it rewards accuracy.
- For creative tasks (e.g., essays or poems), AI goals include matching a high-quality style rather than correctness.
3. Group-Relative Policy Optimization (GRPO): Smarter Answers
In GRPO, multiple answers generated by the model are compared against each other. The best-performing response is optimized to enhance training.
Why does this matter? Before GRPO, models required expensive critic models. Now, DeepSeek simplifies this by creating competitive outcomes internally — it’s like self-improving intelligence!
Evaluation and Benchmarks: How Does DeepSeek-V3 Measure Up?
DeepSeek-V3 excels at reasoning, coding, and natural language generation — but it’s designed for large-scale deployment, which poses challenges:
- Large Computational Requirements Small teams may find it difficult to deploy such a resource-heavy model.
- Room for Speed Improvements While faster than its predecessor, there’s potential to optimize generation speed even further.
- Hardware Dependency The efficiency gains rely heavily on newer, cutting-edge hardware, limiting its accessibility.
DeepSeek’s Bias Problem: What’s Missing in the “Neutrality”?
While DeepSeek-V3 is a technical powerhouse, its avoidance of sensitive and controversial issues reflects a deeper issue of bias cloaked in neutrality. Often, the model opts to sidestep any potentially contentious topics, which may appear “safer” but undermines its application for ethical decision-making under real-world challenges.
Here’s a critical take: DeepSeek’s Bias Flaws. Imagine having an incredibly smart assistant that refuses to offer any opinion — helpful in low-risk situations but unfit to address nuanced or polarizing challenges effectively.
Conclusion:
DeepSeek-V3 is a technical achievement, combining smart architecture (MLA, MTP) with efficient training processes (FP8, FIM). However, its reliance on neutrality to navigate ethical territories exposes potential drawbacks for real-world use.
With that said, this model still sets impressive benchmarks for reasoning and creative outputs, showing immense promise in shaping the next era of AI!
 Previous Blog
Previous Blog





{kind=link}
You Might Like

February 28, 2025
Project EKA – Driving the Future of AI in India
Spread the loveArtificial Intelligence (AI) has long been heralded as the driving force behind global technological revolutions. But what happens when AI isn’t tailored to the needs of its diverse users? Project EKA is answering that question in India. This groundbreaking initiative aims to redefine the AI landscape, bridging the gap between India’s cultural, linguistic, […]

March 7, 2025
What is Data Annotation? And How Can It Help Build Better AI?
Spread the loveIntroduction In the world of digitalised artificial intelligence (AI) and machine learning (ML), data is the core base of innovation. However, raw data alone is not sufficient to train accurate AI models. That’s why data annotation comes forward to resolve this. It is a fundamental process that helps machines to understand and interpret […]

March 6, 2025
Vertical AI Agents: Redefining Business Efficiency and Innovation
Spread the loveThe pace of industry activity is being altered by the evolution of AI technology. Its most recent advancement represents yet another level in Vertical AI systems. This is a cross discipline form of AI strategy that aims to improve automation in decision making and task optimization by heuristically solving all encompassing problems within […]

March 5, 2025
Use of Insurance Data Annotation Services for AI/ML Models
Spread the loveThe integration of artificial intelligence (AI) and machine learning (ML) is rapidly transforming the insurance industry. In order to build reliable AI/ML models, however, thorough data annotation is necessary. Insurance data annotation is a key step in enabling automated systems to read complex insurance documents, identify fraud, and optimize claim processing. If you […]